Deep Learning Note
Machine Learning Overview
LLM Foundations
NeRF
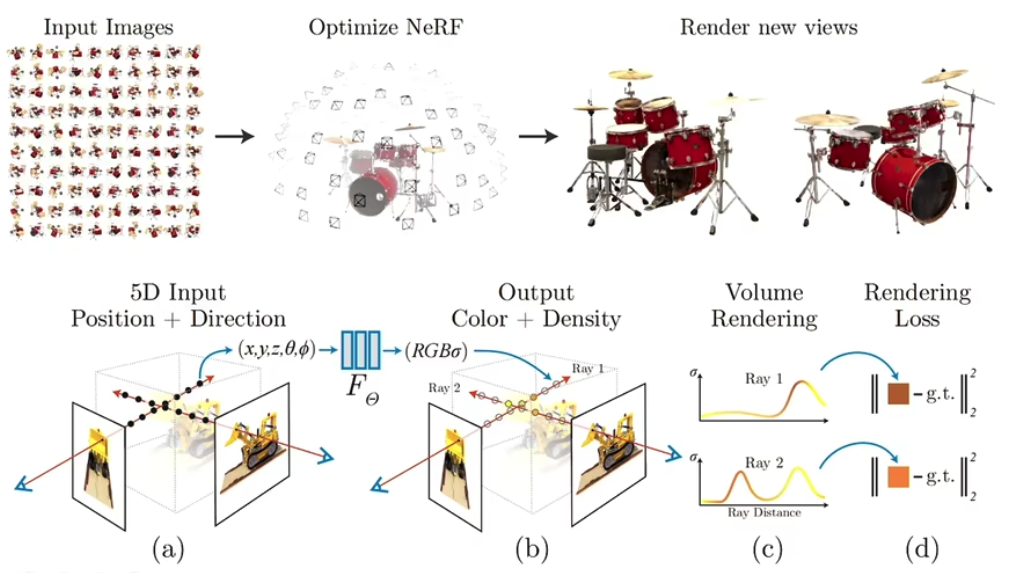
core parts
- Volume rendering
- multilayer perceptron (MLP)
- positional Ecoding
- Hierarchical sampling
Neural Radiance Field is 2D -> 3D process.
Volumn Rendering is 3D -> 2D process.
Shape representations

Appearance representations

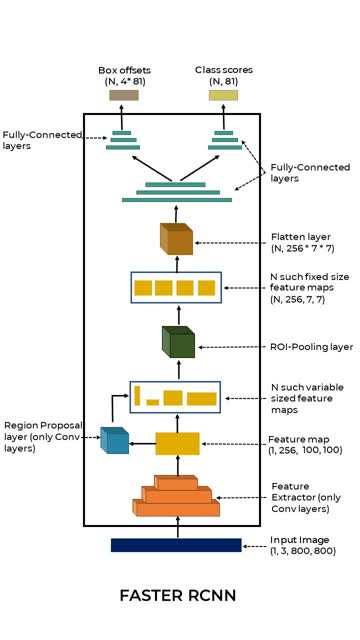
Faster RCNN
- Region Proposal Layer: It predicts N number of objects detected in the feature map.
- ROI Pooling Layer: It resizes the feature-map to a fixed size by pooling.
- Fully Connected Layer: It splits into two separate FC-blocks.
- Predicting the class-scores for the proposed object, e.g. output size [N, 81]
- Box-coordinates for the proposed object, e.g. output size [N, 4 * C] or [N,(x,y,w,h) * C]
Nis number of objects proposed by the Region-Proposal Layer.Cnumber of classes
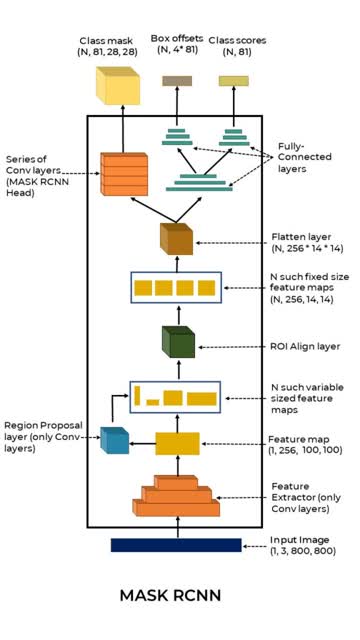
Mask RCNN
- ROI-Align Layer: It Instead of quantization, ROI-Align uses bilinear-interpolation to fill up the values in the fixed-size featuremap.
- Final output size: [N, C, 28, 28]
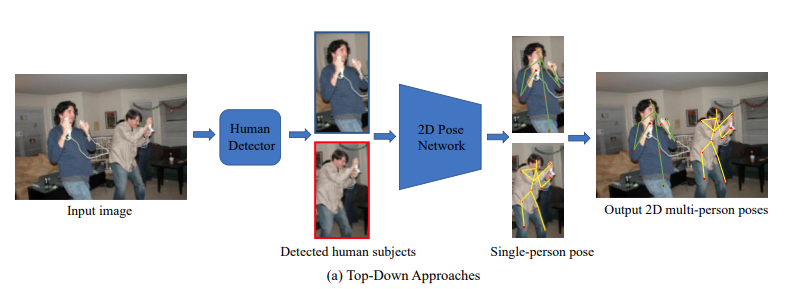
Human Pose Estimation
Top-Down
There are two important parts: a human body detector to obtain person bounding boxes and a single-person pose estimator to predict the locations of keypoints within these bounding boxes.
Deep Learning-Based Human Pose Estimation
Approaches
- CPM
- Hourglass
- CPN
- Simple Baselines
- HRNet
- MSPN
Bottom-Up
The bottom-up has two main steps including body joint detection and joint candidates assembling for individual bodies. In general, top-down has more accurate result, and bottow-up is faster.

Approaches
- Openpose
- Hourglass+Associative Embedding
- HigherHRNet
COCO DATASET FORMAT
The COCO dataset is formatted in JSON and is a collection of
- info
- licenses
- images
- annotations
- categories
- segment info
{
"info": { },
"licenses": [],
"images": [],
"annotations": [],
"categories": [], #Not in Captions annotations
"segment_info": [] #Only in Panoptic annotations
}
info section
"info": {
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
}
licenses section
"licenses": [
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nc/2.0/",
"id": 2,
"name": "Attribution-NonCommercial License"
},
]
images section
The "images" section contains the complete list of images in your dataset. There are no labels, bounding boxes, or segmentations specified in this part, it's simply a list of images and information about each one. Note that coco_url, flickr_url, and date_captured are just for reference. Your deep learning application probably will only need the file_name
Note that image ids need to be unique (among other images), but they do not necessarily need to match the file name
"images": [
{
"license": 4,
"file_name": "000000397133.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000397133.jpg",
"height": 427,
"width": 640,
"date_captured": "2013-11-14 17:02:52",
"flickr_url": "http://farm7.staticflickr.com/6116/6255196340_da26cf2c9e_z.jpg",
"id": 397133
},
{
"license": 1,
"file_name": "000000037777.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000037777.jpg",
"height": 230,
"width": 352,
"date_captured": "2013-11-14 20:55:31",
"flickr_url": "http://farm9.staticflickr.com/8429/7839199426_f6d48aa585_z.jpg",
"id": 37777
},
]
categories section
The "categories" object contains a list of categories (e.g. dog, boat) and each of those belongs to a supercategory (e.g. animal, vehicle).
"categories": [
{"supercategory": "person","id": 1,"name": "person"},
{"supercategory": "vehicle","id": 2,"name": "bicycle"},
{"supercategory": "vehicle","id": 3,"name": "car"},
{"supercategory": "vehicle","id": 4,"name": "motorcycle"},
{"supercategory": "vehicle","id": 5,"name": "airplane"},
{"supercategory": "indoor","id": 89,"name": "hair drier"},
{"supercategory": "indoor","id": 90,"name": "toothbrush"}
]
annotations section
"annotations": [
{
"segmentation": [[510.66,423.01,511.72,420.03,510.45,423.01]],
"area": 702.1057499999998,
"iscrowd": 0,
"image_id": 289343,
"bbox": [473.07,395.93,38.65,28.67],
"category_id": 18,
"id": 1768
},
{
"segmentation": {
"counts": [179,27,392,41,55,20],
"size": [426,640]
},
"area": 220834,
"iscrowd": 1,
"image_id": 250282,
"bbox": [0,34,639,388],
"category_id": 1,
"id": 900100250282
}
]
Image Preprocessing
Mean values for the ImageNet training set are
R=103.93, G=116.77, and B=123.68
When we are ready to pass an image through our network (whether for training or testing), we subtract the mean u from each input channel of the input image:
R = R - mean_r
G = G - mean_g
B = B - mean_b
We may also have a scaling factor sigma which adds in a normalization:
R = (R - mean_r)/sigma
G = (G - mean_g)/sigma
B = (B - mean_b)/sigma
The value of sigma may be the standard deviation across the training set (thereby turning the preprocessing step into a standard score/z-score). However, sigma may also be manually set (versus calculated) to scale the input image space into a particular range — it really depends on the architecture.
YOLO v4
Training
Modify config file paramenter:
batch = 64
subdivisions=16
max_batches: classes number * 2000, and larger than training images, and larger than 6000.
steps: 80% * max_batches, 90% * max_batches
width: 416
height: 416
classes: your training object number
filters: (classes number +5)x3